
Mit is takar ez a kifejezés: prediktív szövegbevitel? Talán úgy lehetne a legegyszerűbben magyarítani e terminus technicust, hogy „előrejelző szövegbevitel”. Ez így sajnos nem túl szerencsés. Ha azt mondom, hogy T9 vagy szókiegészítés/befejezés (word completion), talán már kezd derengeni valami... Ha mégsem, akkor valószínűleg nem az Ön készülékében van a hiba:-). Bár az eljárás története messzebbre nyúlik vissza, széles körben való újrafelfedezését a mobiltechnológia forradalmának köszönhetjük. Gondolok itt elsősorban a mobiltelefonokra, PDA-kra és egyéb hordozható személyi számítógépekre.

A prediktív szövegbevitelt életre hívó probléma abban áll, hogy kis készülékekre bajos volt összezsúfolni annyi billentyűt, amennyi egy hagyományos asztali ún. QWERTY billentyűzeten szerepel. Ezért inkább több karaktert helyeztek el egyetlen gombon. A használónak mindössze annyi a dolga, hogy annyiszor megnyomja az adott gombot, ahányadik betűt el szeretné érni róla. Ez mindenki számára ismert, aki írt már valaha sms-t. A módszer neve „Multi-Tap”. Így viszont jelentősen megnő a szövegbeviteli idő. Mértékegysége a wpm, az az a szó/perc. Hagyományos billentyűzetnél ez olyan 56-57 wpm, kézírásnál kb. 28, Multi-Tap-nél 20-24, T9-nél 40 wpm. Persze ezt befolyásolja az is, hogy hüvelykujjunkat vagy mutatóujjunkat használjuk Még egy mértékegységgel találkozhatunk, ha elmélyedünk a témában, ez pedig a kspc (keystroke per character), vagyis a szükséges leütések száma a kívánt karakterhez. Hagyományos módon a következő leütésekkel tudjuk előhívni pl. a „see you in the pub” szósort: 77773333 s 99966688 s 44466 s 84433 s 78822 (s=szóköz). Van ugyan még egy megoldás, mely kicsit javítja a Multi-Tap hatásfokát: a „két-gombos” technika, de tudomásom szerint nem túl elterjedt. Lényege abban áll, hogy először lenyomjuk a kívánt karaktercsoportot szimbolizáló billentyűt (pl. 5-ös gomb → jkl), majd még egy gombot, aszerint, hogy hányadik betű kell nekünk (pl. 2-es a k betűhöz).
A prediktív szövegbeviteli eljárás újítása abban áll, hogy igyekszik minimalizálni a kspc értéket, és minél inkább maximalizálni a wpm-et (szó/perc). A c betű hagyományos módon történő beírásánál pl. 3 kspc-es értékkel kell számolnunk. A prediktív szövegbevitelnél ezzel szemben csak egyszer kell lenyomnunk azt a billentyűt, amelyen a kívánt karakter szerepel. Pl. a kutya szóhoz a következő leütések szükségeltetnek: 5-8-8-9-2. A program alapvetően szótárakkal dolgozik (van olyan is, amelyik nem, de erről majd később), ahol a szóhoz hozzárendelik, hogy milyen billentyűkombináció szükségeltetik az eléréséhez (a kutyánál ugye 58892), valamint egy gyakorisági értéket. Ha a kutya szót tartja leggyakoribbnak a program, akkor azt fogja elsőnek beadni. Mint az sejthető, agglutináló nyelvek esetében nem elég a szótáralapú megközelítés, egy morfológiai modulra is szükség van.
A problémát az jelenti, hogy egy billentyűkombinációhoz több szó is tartozhat. Ezeket textonimáknak nevezik. Ilyenkor a gép felkínálja nekünk a többi lehetőséget is, amelyek közül választhatunk. Pl. a kakas (52527) szó beírásakor a telefonom lévő T9 (mely a legismertebb és legelterjedtebb prediktív szövegbeviteli szoftver) először a lakást adja ki és csak harmadik lehetőségként a kakast. Nyilvánvaló, hogy a lakás alapvetően gyakoribb szó, mint a kakas.
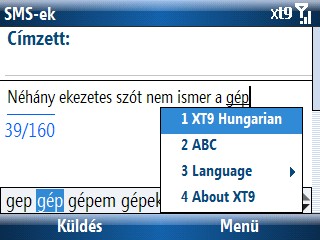
És ezzel elérkeztünk ahhoz a ponthoz, amely a T9-hez hasonló szövegbeviteli eljárások fő gyengéje és amiért oly kevesen használják. Általában nem vagy csak sokadik választható lehetőségként kínálja fel azt a szót, amelyet be szeretnénk írni, vagy pedig hibás alakot javasol. Legtöbbször az összetett szavakkal és azok toldalékolt változataival akadnak gondok. Megpróbáltam beírni a forgatókönyvíróként szót, és a T9 a következőt dobta ki: *forgatókönyvírójént, vagy a színésznőként helyett *színésznőlent, persze beírás közben felkínálja a *színésznőleo alakot is, amelyből nem is tudom milyen magyar szót lehetne képezni. Így a hangzatos mondat, amely szerint egy szóhoz csak annyi leütés szükséges ahány betűből áll, nem állja meg a helyét. Mégpedig azért nem, mert a választható opciók között is gombnyomással kell váltogatnunk (Next).
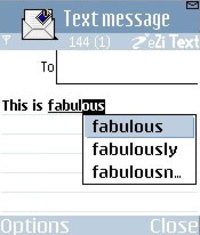
Hogy ezt kiküszöböljék számos segédeljárást építenek be. Ilyen pl. a szókiegészítés vagy szóbefejezés (word completion). Ezzel a funkcióval szerintem sokan találkoztak már webböngészők vagy szövegszerkesztők használata során. Pl. amikor elkezdünk begépelni egy címet www.a stb. és a program felkínálja nekünk a gyakran használt www.a -val kezdődő url-eket, vagy szövegszerkesztők esetében az általunk leggyakrabban használt szavakat. Ez eredményesen akkor működik, ha viszonylag kis korpuszon alkalmazzuk. Manapság a legtöbb prediktív szövegbeviteli rendszert ellátják egy „tanuló” opcióval is. Használata során a szoftver elmenti a szótárban addig nem szereplő szavakat. Az újabb programoknál, pl. az Adaptxt-nél, ez automatikus. Az említett alkalmazást mindemellett rászabadíthatjuk kapott üzeneteinkre, íméljeinkre is, hogy megtanulja belőle az új szavakat. Az Adaptxt viszont nem csak szavakat, hanem gyakran használt mondatokat is el tud sajátítani, majd a kontextus alapján előre megjósolni. Továbbá képes arra is, hogy sorrendiséget tanuljon. A fenti példánál maradva, ha én a kakas szót többször használom, mint a lakást, akkor ezt fogja nekem első helyre tenni.
Ugyanakkor, ahogy korábban említettem, létezik nem szótáralapú alkalmazás is, a LetterWise (LW). A program az egymást követő betűk előfordulási valószínűségén alapszik. Vagyis az adatbázis azt tartalmazza, hogy a szó adott helyén, adott betűk után milyen valószínűséggel milyen betű következik. Tehát „prefix”-ekkel, előtagokkal dolgozik. Az angolban pl. th előtag után a legvalószínűbb, hogy egy e betű következik. Ha nem a kívánt betű jelenik meg, akkor csak egy Next-et kell nyomni, és a kontextus által meghatározott második legvalószínűbb karakterre ugrik. A kutatások szerint a legtöbb Next-et az első betű után kell nyomni, majd egyre kevesebbet. Amíg csak egy karaktert gépeltünk be, az előtag értéke 0, minden újabb karakter után eggyel nő, egészen a maximális hosszig. Ez a módszer jól alkalmazható rövidítéseknél, tulajdonneveknél és idegen szavaknál is. A készítők szerint a LetterWise-zal a felére csökken a kspc (leütés/karakter) érték. Egész pontosan 1.1500, T9-nél ez 1.0072 (bár némely kutató szerint nem ilyen egyértelmű a dolog lásd. http://www.yorku.ca/mack/uist01.html ), Multi-Tap-nél 2.0342. A LW-t egyébként később beépítették egy szótáralapú szoftverükbe is, mely WordWise néven fut. Ha a szótár nem tartalmazza a kívánt szót, akkor átválthatunk LW üzemmódra is, majd így folytathatjuk a beírást. Miután végeztünk a program automatikusan eltárolja az új információ(ka)t. A WordWise PC-n is tesztelhető verziója egyébként letölthető innen: http://www.eatoni.com/demo/abc-english.zip (segítségével lehetőségünk van a hagyományos LW kipróbálására is, igaz mindkettő angol nyelvű).
A kérdés az, hogy mit tartogat számunkra a jövő ezen a téren. Két lehetőséget tartok elképzelhetőnek. Az egyik szerint tökéletesítik a billentyűzetet, és ennek eredményeként a hagyományos szövegbevitel marad az uralkodó mód. A különböző érintőképernyős készülékeknél láthatjuk, hogy ez egy reális út. Igaz, ezeknél többnyire virtuálisan és nem fizikailag valósítják meg azt (lásd. a képeket). Másik lehetőség a szó-, stílus-, mondattanulási funkció fejlesztése, és ezzel együtt a változatosság feltételezhető sorvadása, ami ugye az elektronikusan létrehozott üzenetek egyik fontos jellemzője. Elképzelhetőnek tartom, hogy elég lesz 1-2 betűt vagy szót beírni s máris kész a szándékolt kommunikációs funkciót betöltő mondat. Ez persze nem feltétlenül üdvős, főleg akkor nem, ha a mobilalkalmazásokról átterjed a hagyományos billentyűzettel operáló szoftverekre is. A kognitív deficitről már nem is beszélve…
Ajánlott bejegyzések: